Java HashMap的工作原理(2)
112330 理论 | 2015-8-2-
分析HashMap之前先介绍下什么Hashcode(散列码)。
它是一个int,每个对象都会有一个hashcode,它在内存的存放位置是放在对象的头部(对象头部存放的信息有hashcode,指向Class的引用,和一些有关垃圾回收信息)。具体如何生成hashcode,这个相当复杂,这里不深入探讨。有个问题需要讲的是,如果在你的类中覆盖了Object的equals(Object)方法,那么你必须覆盖hashCode方法,不然,当你使用HashMap,HashSet,HashTable时会出现问题。
1、当调用put(key,value)时,首先获取key的hashcode
int hash = key.hashCode();
2、再把hash通过一下运算得到一个hash
hash ^= (hash >>> 20) ^ (hash >>> 12); int h = hash ^ (hash >>> 7) ^ (hash >>> 4);
为什么要经过这样的运算呢?这就是HashMap的高明之处。
先看个例子,一个十进制数32768(二进制1000 0000 0000 0000),经过上述公式运算之后的结果是35080(二进制1000 1001 0000 1000)。看出来了吗?或许这样还看不出什么,再举个数字61440(二进制1111 0000 0000 0000),运算结果是65263(二进制1111 1110 1110 1111),现在应该很明显了,它的目的是让“1”变的均匀一点,散列的本意就是要尽量均匀分布。那这样有什么意义呢?看第3步。
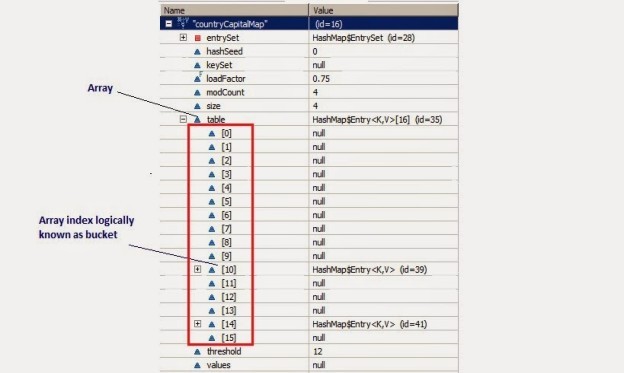
3、得到h之后,把h与HashMap的承载量(HashMap的默认承载量length是16,可以自动变长。在构造HashMap的时候也可以指定一个长度。这个承载量就是上图所描述的数组的长度。)进行逻辑与运算,即 h&(length-1),这样得到的结果就是一个比length小的正数,我们把这个值叫做index。
其实这个index就是索引将要插入的值在数组中的位置。第2步那个算法的意义就是希望能够得出均匀的index,这是HashTable的改进,HashTable中的算法只是把key的hashcode与length相除取余,即hash % length,这样有可能会造成index分布不均匀。还有一点需要说明,HashMap的键可以为null,它的值是放在数组的第一个位置。
4、我们用table[index]表示已经找到的元素需要存储的位置。先判断该位置上有没有元素(这个元素是HashMap内部定义的一个类Entity,基本结构它包含三个类,key,value和指向下一个Entity的next),没有的话就创建一个Entity<K,V>对象,在table[index]位置上插入,这样插入结束;如果有的话,通过链表的遍历方式去逐个遍历,看看有没有已经存在的key,有的话用新的value替换老的value;如果没有,则在table[index]插入该Entity,把原来在table[index]位置上的Entity赋值给新的Entity的next,这样插入结束。
再回头看看前面提到的为什么覆盖了equals方法之后一定要覆盖hashCode方法,很简单,比如,String a = new String(“abc”);String b = new String(“abc”);如果不覆盖hashCode的话,那么a和b的hashCode就会不同,把这两个类当做key存到HashMap中的话就会出现问题,就会和key的唯一性相矛盾。
put方法的实现:
/** * Associates the specified value with the specified key in this map. If the * map previously contained a mapping for the key, the old value is * replaced. * * @param key * key with which the specified value is to be associated * @param value * value to be associated with the specified key * @return the previous value associated with <tt>key</tt>, or <tt>null</tt> * if there was no mapping for <tt>key</tt>. (A <tt>null</tt> return * can also indicate that the map previously associated * <tt>null</tt> with <tt>key</tt>.) */ public V put(K key, V value) { if (key == null) return putForNullKey(value); int hash = hash(key.hashCode()); int i = indexFor(hash, table.length); for (Entry<k , V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); return null; }现在我们一步一步来看下上面的代码。
对key做null检查。如果key是null,会被存储到table[0],因为null的hash值总是0。
key的hashcode()方法会被调用,然后计算hash值。hash值用来找到存储Entry对象的数组的索引。有时候hash函数可能写的很不好,所以JDK的设计者添加了另一个叫做hash()的方法,它接收刚才计算的hash值作为参数。
indexFor(hash,table.length)用来计算在table数组中存储Entry对象的精确的索引。
在我们的例子中已经看到,如果两个key有相同的hash值(也叫冲突),他们会以链表的形式来存储。所以,这里我们就迭代链表。
如果在刚才计算出来的索引位置没有元素,直接把Entry对象放在那个索引上。
如果索引上有元素,然后会进行迭代,一直到Entry->next是null。当前的Entry对象变成链表的下一个节点。
如果我们再次放入同样的key会怎样呢?逻辑上,它应该替换老的value。事实上,它确实是这么做的。在迭代的过程中,会调用equals()方法来检查key的相等性(key.equals(k)),如果这个方法返回true,它就会用当前Entry的value来替换之前的value。
这里我们再来复习put的流程:当我们想一个HashMap中添加一对key-value时,系统首先会计算key的hash值,然后根据hash值确认在table中存储的位置。若该位置没有元素,则直接插入。否则迭代该处元素链表并依此比较其key的hash值。如果两个hash值相等且key值相等(e.hash == hash && ((k = e.key) == key || key.equals(k))),则用新的Entry的value覆盖原来节点的value。如果两个hash值相等但key值不等 ,则将该节点插入该链表的链头。具体的实现过程见addEntry方法,如下:
void addEntry(int hash, K key, V value, int bucketIndex) { //获取bucketIndex处的Entry Entry<K, V> e = table[bucketIndex]; //将新创建的 Entry 放入 bucketIndex 索引处,并让新的 Entry 指向原来的 Entry table[bucketIndex] = new Entry<K, V>(hash, key, value, e); //若HashMap中元素的个数超过极限了,则容量扩大两倍 if (size++ >= threshold) resize(2 * table.length); }这个方法中有两点需要注意:
一是链的产生。这是一个非常优雅的设计。系统总是将新的Entry对象添加到bucketIndex处。如果bucketIndex处已经有了对象,那么新添加的Entry对象将指向原有的Entry对象,形成一条Entry链,但是若bucketIndex处没有Entry对象,也就是e==null,那么新添加的Entry对象指向null,也就不会产生Entry链了。
二、扩容问题。
随着HashMap中元素的数量越来越多,发生碰撞的概率就越来越大,所产生的链表长度就会越来越长,这样势必会影响HashMap的速度,为了保证HashMap的效率,系统必须要在某个临界点进行扩容处理。该临界点在当HashMap中元素的数量等于table数组长度*加载因子。但是扩容是一个非常耗时的过程,因为它需要重新计算这些数据在新table数组中的位置并进行复制处理。所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。
get方法的实现:
/** * Returns the value to which the specified key is mapped, or {@code null} * if this map contains no mapping for the key. * * <p> * More formally, if this map contains a mapping from a key {@code k} to a * value {@code v} such that {@code (key==null ? k==null : * key.equals(k))}, then this method returns {@code v}; otherwise it returns * {@code null}. (There can be at most one such mapping.) * * </p><p> * A return value of {@code null} does not <i>necessarily</i> indicate that * the map contains no mapping for the key; it's also possible that the map * explicitly maps the key to {@code null}. The {@link #containsKey * containsKey} operation may be used to distinguish these two cases. * * @see #put(Object, Object) */ public V get(Object key) { if (key == null) return getForNullKey(); int hash = hash(key.hashCode()); for (Entry<k , V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) return e.value; } return null; }当你理解了hashmap的put的工作原理,理解get的工作原理就非常简单了。当你传递一个key从hashmap总获取value的时候:
对key进行null检查。如果key是null,table[0]这个位置的元素将被返回。
key的hashcode()方法被调用,然后计算hash值。
indexFor(hash,table.length)用来计算要获取的Entry对象在table数组中的精确的位置,使用刚才计算的hash值。
在获取了table数组的索引之后,会迭代链表,调用equals()方法检查key的相等性,如果equals()方法返回true,get方法返回Entry对象的value,否则,返回null。
要牢记以下关键点:
HashMap有一个叫做Entry的内部类,它用来存储key-value对。
上面的Entry对象是存储在一个叫做table的Entry数组中。
table的索引在逻辑上叫做“桶”(bucket),它存储了链表的第一个元素。
key的hashcode()方法用来找到Entry对象所在的桶。
如果两个key有相同的hash值,他们会被放在table数组的同一个桶里面。
key的equals()方法用来确保key的唯一性。
value对象的equals()和hashcode()方法根本一点用也没有。
-
猜你喜欢
- 个人资料
-

Java小强
未曾清贫难成人,不经打击老天真。
自古英雄出炼狱,从来富贵入凡尘。
- 站内搜索
-
- 文章分类
- 最新文章
- 热门文章
发表评论: